Manuel Interlinear Text Editor (ITE)
SOMMAIRE
I. La fenêtre principale
La fenêtre principale est une fenêtre vide qui sert à héberger l'ensemble de toutes les fenêtres que vous ouvrirez par la suite. Elle possède une barre de menu dans sa partie supérieure comportant les quatre menus: File, Windows, Tools et Help.
Le menu File
Le menu File comporte 4 options: New, Open..., Load lexicon from file... et Quit.
- L'option
Newpermet de créer un nouveau document d'annotations vide. Lors de son activation, une fenêtre de dialogue s'ouvre vous permettant de définir les chemins d'accès vers les différents objets de l'analyse (texte, phrase, mot, morphème, transcription, traduction, glose, etc.). Les valeurs par défaut de ces champs sont celles correspondant à la DTD du programme "Archivage" du LACITO.
Si vos documents d'annotation ne sont pas structurés de la même manière que ceux du programme "Archivage" du LACITO, c'est à dire que vous n'utilisez pas la même DTD, vous devez impérativement modifier à la fois les paramètres XPath pour permettre à ITE de parcourir vos documents, mais vous devez aussi créer une feuille de styles XSLT pour permettre à ITE de modifier les documents. Cette feuille de styles doit accepter 3 paramètres
- Le paramètre
whatindique à la feuille de styles quelle action elle doit effectuer. Les valeurs possibles sont:createLevelcréation d'un nouvel objet (texte, phrase, mot ou morphème)createAnnotationcréation d'une nouvelle annotation (transcription ou traduction/glose)embedLevelencapsulation un objet (texte, phrase, mot ou morphème) dans un autre objet d'un niveau suppérieurembedAnnotationencapsulation d'une annotation (transcription ou traduction/glose) dans un objet (texte, phrase, mot ou morphème)
- Le paramètre
levelest utilisé lorsque le paramètrewhat="createLevel", pour indiquer le niveau de l'objet à créer. Il peut prendre l'une des valeurs:[doc, text, sentence, word, morpheme]. Lorsque le paramètrewhat="createAnnotation", il indique alors pour quel type d'objet l'annotation doit être crée. - Le paramètre
annotationest utilisé lorsque le paramètrewhat="createAnnotation"pour indiquer le type d'annotation choisi parmi les valeurs[translation, transcription]
Vous trouverez trois exemples d'implementation dans les sources (
modifications.xsl,modifications_en.xsletmodifications_fr.xsl).Les différents ensembles de paramètres que vous souhaitez utiliser peuvent être signalés au sein d'un document XML (fichier
prof.xml) placé dans le répertoire de lancement de l'application. Sa structure est relativement simple: Il s'agit d'indiquer dans les paramètresvalue, l'url de vos définitions d'options, et d'indiquer dans l'attributname, un nom qui apparaitra dans la liste en bas à gauche de la fenêtre de paramétrage, et par lequel vous pourrez les invoquer.<?xml version="1.0" encoding="iso-8859-1"?> <profile> <item name="option1" value="file://c:/ITE/options1.xml"/> <item name="option2" value="file://c:/ITE/options2.xml"/> </profile>
Les documents définissant les paramètres proprement dits sont aussi des documents XML que vous pouvez placer où vous voulez, à partir du moment où vous avez indiqué correctement leurs urls dans le fichier
prof.xml. Pour définir un nouveau document inspirez vous de ceux (enOptions.xml,frOptions.xmletdefault.xml) présents dans la distribution des sources.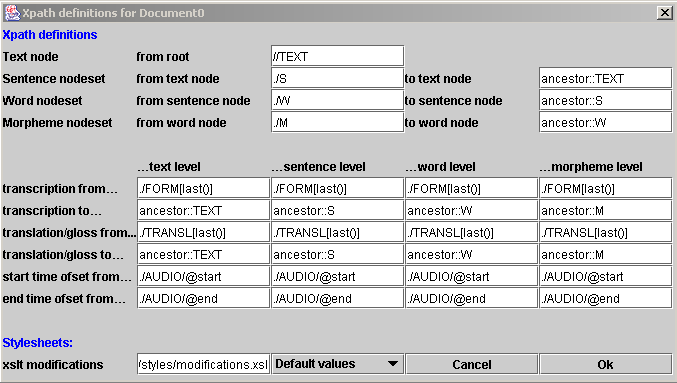
Paramétrage des xpath - Le paramètre
- L'option
Open...permet d'ouvrir un document d'annotations existant. Comme avec l'optionNew, son activation provoque l'ouverture d'une fenêtre de dialogue vous permettant de définir les chemins d'accès vers les différents objets de l'analyse. Plusieurs fichiers d'annotation peuvent être ouverts en même temps, et ITE en tiendra compte dans la fabrication de ses lexiques, concordances, etc. En revanche, à un moment donné, seule une seule fenêtre d'édition peut être active. L'ensemble des fichiers ouverts constitue un "corpus". - L'option
Load lexicon from file...permet de charger en une fois tout un lexique. Celui-ci sera utilisé soit pour gloser les mots (optionwords lexicondu sous-menu), soit pour gloser les morphèmes (optionmorphemes lexicondu sous-menu).
La DTD d'un lexique est la suivante (l'attributnbpermet de donner la fréquence d'apparition de l'unité dans le corpus):<!ELEMENT lexique (item*) > <!ELEMENT item (transcription,glose) > <!ATTLIST item nb CDATA #REQUIRED> <!ELEMENT transcription (#PCDATA) > <!ELEMENT glose (#PCDATA) >
- L'option
Quitpermet de quitter le logiciel. Ce dernier vous demandera pour chaque fichier ouvert et modifié depuis la dernière sauvegarde si vous souhaitez enregistrer les modifications.
Le menu Windows
Le menu Windows comporte autant d'options que vous avez ouvert de documents d'annotations. Le nom des options reprend les noms des fichiers xml correspondants. Valider une option permet de mettre au premier plan la fenêtre d'édition du document correspondant.
Le menu Tools
Le menu Tools comporte trois options: Lexicon..., Concordances... et Preferences. Les deux premières options présentent respectivement le lexique et les concordances calculées sur l'ensemble des fichiers d'annotations en cours d'édition. Choisir une de ces options ouvre dans un premier temps un fenêtre de dialogue permettant de paramétrer l'opération, puis dans un deuxième temps une fenêtre de résultats. L'option Preferences permet de consulter/modifier les préférences d'ITE
- L'option
Lexicon...Cette option permet de lister le lexique utilisé sur l'ensemble des fichiers en cours d'édition. Ce lexique est concaténé avec celui qui a éventuellement été chargé indépendament par l'option
Load lexicon from file...du menuFile. La fenêtre de dialogue permet de choisir la granularité de l'analyse (mots ou morphèmes)
Paramétrage pour l'affichage du lexiqueUne fois le niveau d'analyse choisi, les résultats se présentent comme une simple liste de trois colonnes (transcription, glose, fréquence). Ces trois colonnes peuvent être déplacées et triées à volonté (en cliquant sur le titre de la colonne). Vous pouvez sauvegarder ce lexique pour vous en servir par ailleurs (cf. l'option
Load lexicon from file...du menuFile).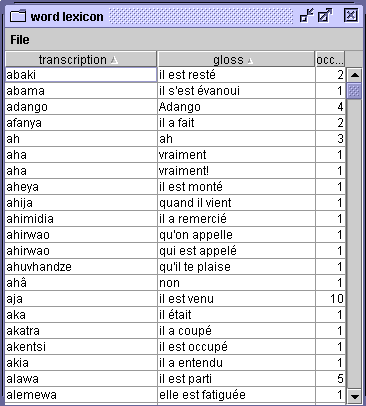
Fenêtre d'affichage du lexique - L'option
Concordances...Cette option permet de d'extraire du corpus (les fichiers en cours d'édition), un certain nombre d'unités et de les présenter dans leur contexte d'apparition.
Les paramètres sont au nombre de 5:- Le pattern recherché sous forme d'une expression régulière. Par exemple
"a.*"va rechercher toutes les unités qui commencent par"a" - Une condition supplémentaire à la recherche exprimée sous la forme d'un prédicat XPath. Par exemple: le predicat
contains(@transl, "m")conserve, parmi les éléments sélectionnés, uniquement ceux dont la traduction comporte le caractèrem. - Le niveau sur lequel va porter l'analyse (mot ou morphème)
- La portée du contexte (phrase ou texte)
- Le nombre de mots retenus pour chaque contexte (droite et gauche)

Paramétrage des concordancesUne fois les paramètres de l'analyse choisis, les résultats se présentent comme une simple liste de quatre colonnes (identifiant, contexte gauche, unité recherchée, contexte droit). Ces quatre colonnes peuvent être déplacées et triées à volonté (en cliquant sur le titre de la colonne). Pour faire un tri secondaire, cliquez sur la colonne avec la touche
Ctrlenfoncée.
Fenêtre d'affichage des concordancesLes concordances sont utiles pour trouver des erreurs dans la transcription. Une fois l'erreur identifiée, vous pouvez éditer l'unité en double-cliquant sur la ligne correspondante, l'éditeur du document passe alors au premier plan et présente la phrase qui contient l'unité.
L'apparence de la concordance peut être modifiée par une feuille de styles (fichierconc.xsl) placée dans le repertoire de lancement de l'application. Si ce fichier n'existe pas c'est le fichier par défaut d'ITE qui sera utilisé. Cette feuille de styles doit implémenter trois règles (xsl:template) qui ont pour nom:rightContextavec les paramètres:scope(valeurs possibles:'text'ou'sentence')nbWords(valeurs possibles: un chiffre)
leftContextavec les paramètres:scope(valeurs possibles:'text'ou'sentence')nbWords(valeurs possibles: un chiffre)
itemForm
le noeud courant est soit un mot soit un morphème.
Ce fichier peut définir des règles d'affichage comme par exemple: Pour insérer des tirets entre les morphèmes d'un même mot<xsl:template match="W/M[position()!=last()]/@form"> <xsl:value-of select="."/><xsl:text>-</xsl:text> </xsl:template>
Tout ce que vous avez besoin de savoir, pour écrire votre propre feuille de styles, est que la DTD interne d'un corpus dans ITE est :
<!-- la racine --> <!ELEMENT corpus (S*) > <!-- S pour Phrase (sentence) --> <!ELEMENT S (W*) > <!ATTLIST S id CDATA #REQUIRED win CDATA #REQUIRED pos CDATA #REQUIRED> <!-- + tous les autres attributs que vous avez créé --> <!-- W pour Mot (Word) --> <!-- form pour transcription --> <!-- transl pour glose --> <!ELEMENT W (M*) > <!ATTLIST W form CDATA #REQUIRED transl CDATA #REQUIRED> <!-- + tous les autres attributs que vous avez créé --> <!-- M pour Morpheme --> <!-- form pour transcription --> <!-- transl pour glose --> <!ELEMENT M EMPTY > <!ATTLIST M form CDATA #REQUIRED transl CDATA #REQUIRED> <!-- + tous les autres attributs que vous avez créé -->
- Le pattern recherché sous forme d'une expression régulière. Par exemple
-
L'option
Preferencespermet de consulter/modifier les préférences d'ITE. Deux boutons permettent aussi de sauvegarder l'ensemble de ces préférences dans un fichierSave to file...ou bien de les charger à partir d'un fichierLoad from file....regex (text > sentence)l'expression régulière qui permet de découper automatiquement un texte en phrases.regex (sentence > word)l'expression régulière qui permet de découper automatiquement une phrase en mots.regex (word > morphèmes)l'expression régulière qui permet de découper automatiquement un mot en morphèmes.transcription sort orderla définition de l'odre alphabétique a utiliser pour les transcriptions. La syntaxe formelle qui doit être utilisée pour cette déclaration est définit dans la classes javajava.text.RuleBasedCollator. Elle est relativement simple et intuitive et est résumée ci-dessous.glose sort orderla définition de l'odre alphabétique a utiliser pour les gloses.
La syntaxe utilisée dans les définitions des ordres alphabétiques est un suite de règles qui peuvent être de 3 types:
<modifier>
<relation> <text-argument>
<reset> <text-argument>Text-Argument: N'importe quelle séquence de caractères à l'exception des caractères d'espacement et des caractères utilisés pour les règles. Ces caractères doivent être mis entre quotes simples si on souhaite s'en servir pour eux-même.Modifier: deux modificateurs permettent d'orienter l'ordre alphabétique.
'@' : Utilisation de l'algorithme de tri à rebour (pour le tri secondaire), comme pour les accents du français.
'!' : Utilisation de l'algorithme de tri basé sur l'inversion voyelle-consonne du Thai/Lao.Relation: Les relations peuvent être des 4 types suivants:
'<' : Plus grand, dans le sens d'une différence entre lettres (ordre primaire)
';' : Plus grand, dans le sens d'une différence d'accent (ordre secondaire)
',' : Plus grand, dans le sens d'une différence de casse (ordre tertiaire)
'=' : EgalitéReset: Le caractère '&' est utilisé pour compacter ou étendre les règles. Les expressions suivantes sont équivalents:a < b < cpeut s'écrire aussia < b & b < c.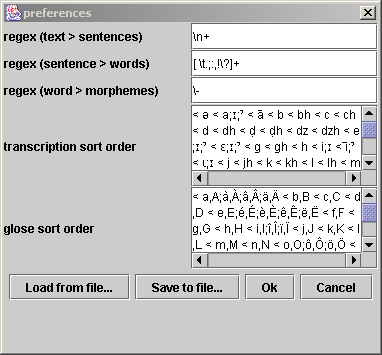
Fenêtre des préférences
Le menu Help
L'option About... du menu Help affiche dans une fenêtre la référence à la GNU General Public License.
II. La fenêtre d'édition des annotations
Une fenêtre d'édition permet de saisir un certain nombre d'annotations linguistiques dans une présentation adéquate et une interface relativement conviviale. Elle possède une barre de menu dans sa partie supérieure comportant les menus: File, Edit et Tools. Juste en dessous de la barre des menus se trouve une série de quatre onglets (Text, Sentence, Word et Morpheme) permettant d'accéder aux vues correspondantes sur les annotations. La partie centrale de la fenêtre comporte les différents champs d'édition de l'annotation (transcription et traduction) présentés différemment selon la vue choisie. Enfin en bas de la fenêtre se trouvent des boutons de navigation d'une phrase à l'autre et éventuellement le player du fichier media (vidéo ou son) correspondant à l'annotation en cours.
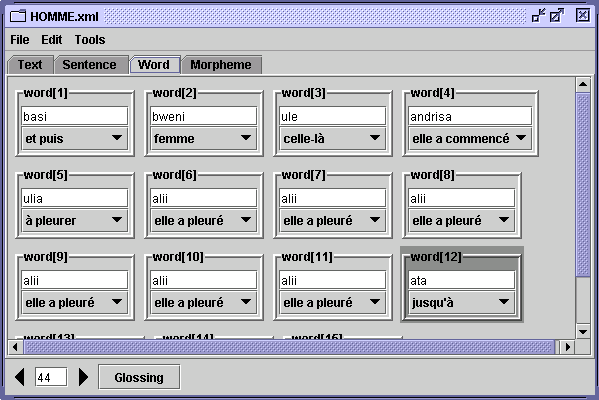
Fenêtre d'édition
L'onglet Text
L'onglet Text affiche dans la fenêtre deux champs: un pour la transcription du texte (celui du haut), un autre pour sa traduction (celui du bas). Les contenus de ces champs peuvent se dérouler sur plusieurs lignes.
L'onglet Sentence
L'onglet Sentence affiche dans la fenêtre deux champs: un pour la transcription de la phrase (celui du haut), un autre pour sa traduction (celui du bas). Les contenus de ces champs doivent tenir sur une seule ligne.
L'onglet Word
L'onglet Word affiche dans la fenêtre autant de cadres qu'il y a de mots dans la phrase. Chaque cadre comprend un champ pour saisir la transcription du mot (haut du cadre), et un menu affichant la glose du mot (bas du cadre). Pour saisir ou changer la glose d'un mot, il faut choisir dans le menu affichant la glose l'option Other gloss.... La liste de toute les gloses existantes est alors ajoutée au menu. Vous pouvez alors choisir une glose parmi cet ensemble, ou bien, le cas échéant saisir une nouvelle glose dans le champ de saisie de ce menu.
L'onglet Morpheme
L'onglet Morpheme affiche dans la fenêtre autant de cadres qu'il y a de mots dans la phrase. Chaque cadre comprend autant de sous-cadres qu'il y a de morphèmes dans le mot. Ces sous-cadres comportent chacun un champ pour saisir la transcription du morphème (haut du sous-cadre), et un menu affichant la glose du morphème (bas du sous-cadre). Pour saisir ou changer une glose, il faut, comme pour les mots (Cf. L'onglet Word), choisir dans le menu affichant la glose l'option Other gloss....
Les menus contextuels
Quel que soit le niveau choisi avec l'onglet correspondant, la fenêtre affiche un certain nombre de champs permettant de modifier le contenu de l'annotation linguistique. A chacun de ces champs, est associé un menu contextuel qui permet en général au minimum les 3 possibilités suivantes :
show attributes: permet de modifier, d'ajouter ou de supprimer des attributs à l'élément.show source: permet d'afficher le contenu de l'élément en mode source.transform...: permet d'opérer des transformations sur l'élément à l'aide de feuilles de styles XSL-T.
Ces options sont principalement pour les utilisateurs avancés. Elles sont indiquées dans le tableau qui suit par l'abréviation "AST" (attributes-source-transform). En plus de ces fonctions, certains menus contextuels offrent l'accès à des fonctions qui ne demandent aucune connaissance particulière sur XML. Elles sont récapitulées dans le tableau ci-dessous.
A noter que lorsqu'une transcription à un nouveau niveau est produite en divisant ou en rassemblant les unités d'une transcription existante (1) la transcription source au niveau d'origine reste inchangée, (2) la nouvelle transcription crée devient un entité séparée, indépendante de la transcription source. Les modifications ultérieures de l'une d'elles n'auront aucun effet sur l'autre. Par exemple, la transcription d'un morpheme peut être crée à partir de la transcription phonétique de la phrase puis éditée à la main pour en faire une transcription morpho-phonologique.
| onglet | click droit | options du menu contextuel |
|---|---|---|
| Text | dans la fenêtre en dehors des champs | AST du texte |
| Text | dans le champ du haut | AST de la transcription du texte
découpage du texte en phrases composition de la transcription du texte à partir des transcriptions de ses phrases |
| Text | dans le champ du bas | AST de la traduction du texte
composition de la traduction du texte à partir des traduction de ses phrases |
| Sentence | dans la fenêtre en dehors des champs | AST de la phrase
insérer, dupliquer, supprimer une phrase |
| Sentence | dans le champ du haut | AST de la phrase
découpage de la transcription de la phrase en mots et/ou en morphèmes composition de la transcription de la phrase à partir des transcriptions de ses mots ou de ses morphèmes |
| Sentence | dans l'éditeur du bas | AST de la traduction de la phrase |
| Word | dans la fenêtre en dehors des cadres | AST de la phrase
insérer, dupliquer, supprimer une phrase ajouter un mot |
| Word | sur le cadre d'un mot | AST du mot |
| Word | dans le champ du haut d'un mot | AST de la transcription du mot
découpage de la transcription du mot en morphèmes découpage de la transcription du mot en deux composition de la transcription du mot à partir des transcriptions de ses morphèmes |
| Word | dans le menu déroulant (en bas) d'un mot | AST de la glose du mot |
| Morpheme | dans la fenêtre en dehors des cadres | AST de la phrase
insérer, dupliquer, supprimer une phrase ajouter un mot |
| Morpheme | sur le cadre d'un mot | AST du mot
ajouter un morphème |
| Morpheme | sur le cadre d'un morphème | AST du morphème |
| Morpheme | dans le champ du haut d'un morphème | AST de la transcription du morphème
découpage du morphème en deux |
| Morpheme | dans le menu déroulant (en bas) d'un morphème | AST de la glose du morphème |
Le menu File
Le menu File comporte 4 options: Load media file..., Save, Save as... et Close. Les 3 dernières options ont les comportements classiques et attendus pour des options portant ces noms. La première option, Load media file..., permet d'ouvrir dans la fenêtre d'édition le fichier d'enregistrement (audio ou vidéo) correspondant à l'annotation. Dans le dialogue d'ouverture vous devez aussi choisir l'outil de lecture pour ce fichier: soit Java Media Framework (JMF) soit QuickTime for Java (QT4J). Une fois l'outil de lecture et le fichier choisis et après avoir validé le dialogue, un slider apparaît en bas de la fenêtre avec eventuellement un espace reservé à l'image de la vidéo. Enfin pour chaque niveau d'annotation l'option play... est ajoutée dans le menu contextuel d'un objet si celui-ci comporte des valeurs de début et de fin. Pour le niveau sentence une icône de haut-parleur s'affiche également dans la fenêtre.
Le menu Edit
L'option Undo... annule le dernier changement que vous avez fait dans la fenêtre. Un deuxième Undo... annule ce que vous aviez fait avant lui...
L'option Redo... refait la dernière modification que vous avez annulée. Un autre Redo... refait ce que vous aviez annulé avant celle-ci...
L'option Find... du menu Edit permet de rechercher une chaîne de caractères particulière dans une partie des annotations. La validation de cette option affiche une fenêtre de dialogue permettant de paramétrer la recherche.

Fenêtre de recherche
- La recherche peut porter sur : la transcription d'un mot ou d'un morphème, la glose d'un mot ou d'un morphème.
- La chaîne de caractères peut être exprimée au moyen d'une expression régulière
- Si la chaîne de caractères n'est pas une expression régulière, il est possible de la définir comme un morceau de ce que l'on cherche ou comme la chose entière.
- La recherche peut commencer à la première phrase ou à la phrase active: celle qui est affichée dans la fenêtre
- Il est aussi possible d'ajouter des contraintes à la recherche portant sur n'importe quelle partie de l'annotation. Les conditions sont à ajouter sous la forme d'un prédicat xpath. Il faut pour cela que vous connaissiez votre structure de document et garder à l'esprit que le noeud courant est soit le mot (recherches dans
word transcriptionouword gloss) soit le morphème (recherches dansmorpheme transcriptionoumorpheme gloss). Par exemple, dans la DTD du LACITO, le prédicatancestor::S/@who='loc1'restreindra la recherche uniquement aux phrases du locuteurloc1.
L'option Replace... du menu Edit permet de rechercher une chaîne de caractères particulière dans une partie des annotations et de la remplacer par une autre. La validation de cette option affiche une fenêtre de dialogue permettant de paramétrer la recherche, par exemple pour rechercher/remplacer des mots un par un bouton Replace ou bien en une seule fois dans tous le document par le bouton Replace all.
Le menu Tools
Le menu Tools comporte la seule option Apply stylesheet... qui permet d'appliquer une transformation XSLT sur le document
L'option Apply stylesheet... permet d'appliquer une feuille de styles (XSLT) de son choix au document en cours d'édition et de présenter le résultat en code source dans un éditeur de texte, de remplacer le document en cours, ou bien d'afficher le résultat dans un interpréteur HTML, dans le cas où le résultat de la transformation serait un document HTML (version 3.2).
III. Références
Références normatives
- Tim Bray, Jean Paoli, C. M. Sperberg-McQueen, Eve Maler et François Yergeau (Eds). Extensible Markup Language (XML) 1.0 (Third Edition). Recommendation W3C du 04 février 2004.
- James Clark et Steve DeRose (Eds). XML Path Language (XPath) Version 1.0. Recommendation W3C du 16 novembre 1999.
- James Clark (Ed). XSL Transformations (XSLT) Version 1.0. Recommendation W3C du 16 novembre 1999.
- La page web du Consortium Unicode http://www.unicode.org/
Liens
- Brêve présentation des expressions régulières sur mon site (expressions régulières).
Vous trouverez beaucoup plus de renseignements en tapant une requête de type"Expressions Regulieres"ouRegexdans votre moteur de recherche favori. - Site web du programme "Archivage" du LACITO (http://lacito.vjf.cnrs.fr/archivage/).
